
RAG ne suffit plus ? Quand passer à GraphRAG pour ta base de connaissances

Tu utilises déjà du RAG pour répondre aux questions sur tes docs internes ( Si tu veux un rappel sur ce que c'est le Rag, tu peux te référer à cet article ). Ça marche bien tant que les requêtes restent locales et factuelles. Mais dès que la question te demande de croiser des informations dispersées dans tes différents documents (procédures, tickets, FAQ, docs projet), le RAG classique décroche. Dans ce papier, je t’explique pourquoi, ce que GraphRAG change, et quand basculer sans te compliquer la vie.
Ce qui coince avec le RAG « classique »
Le RAG standard fait une recherche de passages, puis génère une réponse à partir de ces passages. Il retrouve des morceaux pertinents, mais perd les relations entre entités (produits, versions, incidents) et loupe la vue d’ensemble. Tu peux élargir la fenêtre de contexte : le coût et la latence montent, et la cohérence globale chute.
Ce que GraphRAG ajoute (et pourquoi ça change le jeu)
GraphRAG commence par extraire un graphe de connaissances de tes textes (nœuds = entités/concepts, arêtes = relations), puis organise ce graphe en communautés hiérarchiques. Sur cette structure, il propose deux modes complémentaires :
- Local search : Le système fouille un petit morceau du graphe (un sous-ensemble de docs liés) pour détailler un point.
- Global search : Le système parcourt plusieurs zones du graphe et synthétise ce qu’il trouve en s’appuyant sur des “rapports de communauté” (des résumés par clusters de docs).
Prenon un exemple réaliste d'un support client sur 90 jours: une PME B2B gère : une FAQ (Markdown), des procédures internes (Google Docs), et 50 000 tickets support (CSV/helpdesk).
Question. « Quelles sont les trois causes racines des retards de paiement signalés ces 90 derniers jours, et quelles actions correctives documentées existent ? »
Avec RAG classique. Le RAG me renvoie quelques extraits utiles, mais éparpillés dans différents documents. Rien ne regroupe automatiquement ces preuves par version ou par équipe, donc je dois faire la synthèse moi-même.
Avec GraphRAG. On construit d’abord une carte des liens entre tes infos (par ex. version → module → incident → correctif). Ensuite, pour une question large, l’agent lit les mini-synthèses par thème (ex. “paiement / intégrations”, “v3.4 / webhook”), garde celles qui servent la question, puis assemble une réponse sourcée : les 3 causes et les actions correspondantes.
Résultat : des réponses plus complètes et expliquées quand la question demande de couvrir large.
Quand passer (vraiment) à GraphRAG ?
1) Tes questions demandent une vision corpus-wide: tu poses des « pourquoi / tendances / synthèses » multi-docs et multi-équipes. Le gain du global search dépasse le surcoût d’indexation.
2) Tu dois relier des entités (produits, versions, comptes, lieux): Si la relation entre éléments compte autant que le contenu, le graphe change la donne : on modélise explicitement ces liens.
3) Tu fais face à des requêtes multi-étapes :La fidélité chute quand il faut agréger des preuves hétérogènes. Le graphe sert d’ossature logique pour garder le fil.
4) Tu veux des réponses sourcées et auditables : GraphRAG facilite l’attribution (nœuds/arêtes → passages) et la traçabilité des synthèses : utile pour conformité et relecture.
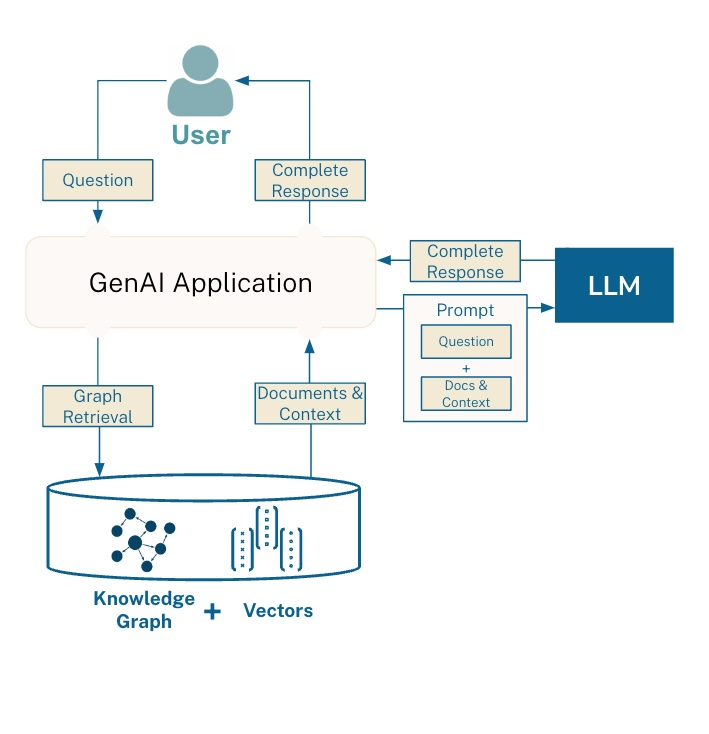
Ce que ça change dans ton stack n8n:
Objectif simple : arrêter de chercher au hasard dans des dossiers, et obtenir des réponses sourcées qui tiennent la route. Sans code, avec n8n.
Je branche n8n à tes sources (Drive, Notion, helpdesk…). Un petit robot de nuit passe, lit les documents, et fabrique deux choses :
- des étiquettes par thème (ex. « paiements », « v3.4 », « intégrations ») ;
- des fiches très courtes par thème qui résument l’essentiel et pointent vers les passages utiles.
Tu peux voir ça comme une mini-carte du savoir de l’entreprise : on ne garde pas tout le texte, on garde ce qui aide à répondre.
ainsi, quand tu poses une question, l'agent IA choisis le chemin :
- Mode “zoom” (questions simples) : il pioche 2–3 passages précis et je réponds.
- Mode “panorama” (questions larges) : Il prends de la hauteur, rassemble quelques fiches-thèmes pertinentes (5–10 max), puis te livre une synthèse claire avec les liens vers les sources.
Résultat : tu as une réponse qui explique, qui relie les points et qui cite d’où ça vient.
Et chaque réponse laisse une trace : la question, ce qui a été consulté, la réponse, les sources. J’appelle ça le journal de bord. On ajoute un petit contrôle qualité sur 10 questions “test” (toujours les mêmes) pour vérifier que les réponses restent :
- fidèles aux sources,
- complètes (pas d’angle mort),
- utiles pour le métier.
Si ça dévie, on corrige les étiquettes ou les fiches. Pas besoin de coder.
Plan d’action en 5 gestes (no-code)
- Choisis un périmètre pilote (par ex. “retards de paiement”, 2–3 sources de docs).
- Laisse le robot de nuit créer les étiquettes et les fiches-thèmes.
- Teste 10 questions réelles en “zoom” et en “panorama”.
- Regarde le journal de bord : sources citées, clarté des réponses, temps gagné.
- Ajuste le curseur (thèmes, fréquence de mise à jour) et déploie au reste des équipes.
Si tes questions métier demandent des synthèses transverses et des explications sourcées, le RAG seul va plafonner. GraphRAG apporte la structure manquante : un graphe pour penser en relations, et un global search qui sait choisir ce qu’il faut agréger. Commence petit, prouve l’impact sur 10 questions réelles, puis route intelligemment RAG ↔ GraphRAG selon le besoin.