
Parallélisation : l’arme cachée pour rendre tes systèmes IA plus rapides et plus efficaces

Tu as déjà vu comment le chaînage donne de la structure et comment le routing apporte du discernement. Il manque une brique pour passer un cap en vitesse : la parallélisation. L’idée est simple à énoncer et puissante à l’usage : lancer plusieurs sous-tâches en même temps dès qu’elles n’ont pas besoin l’une de l’autre. Au lieu d’attendre que la recherche d’une source finisse pour commencer la suivante, tu interroges plusieurs canaux à la fois, puis tu ne synthétises qu’une fois toutes les réponses sur la table.
Concrètement, imagine un agent chargé d’enquêter sur une entreprise. En séquentiel, il fouille la presse, puis les réseaux sociaux, puis les données financières, puis ta base interne. En parallèle, il lance ces quatre travaux simultanément et ne patiente que pour la phase de synthèse. Même logique pour un assistant marketing qui prépare un email : l’objet, le corps, l’image et le call-to-action peuvent être générés en parallèle avant l’assemblage final. Le résultat, c’est le même livrable… livré beaucoup plus vite.
Cette approche brille dès que la latence vient d’ailleurs que du modèle lui-même : appels API, requêtes bases de données, téléchargements de documents. Tant que les tâches sont indépendantes, tu gagnes un facteur temps sans sacrifier la rigueur du processus.
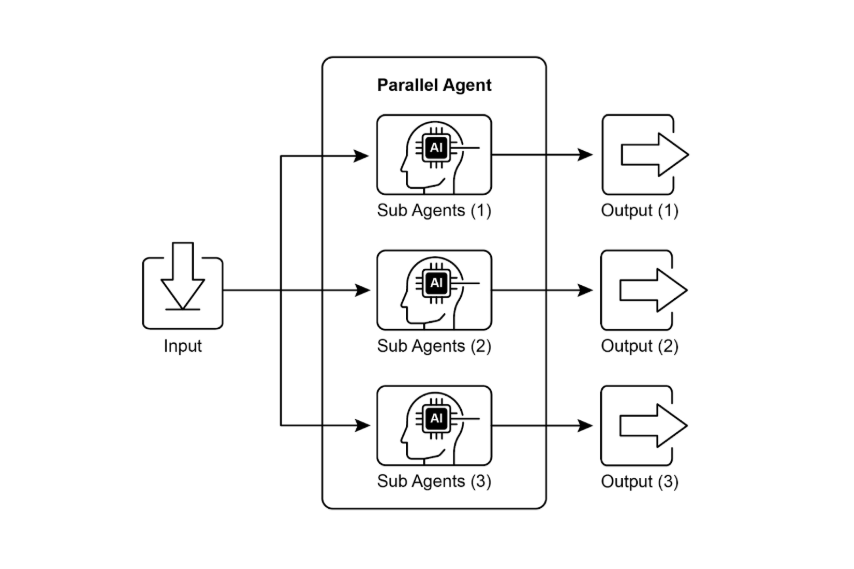
Le principe de la parallélisation
Un workflow classique fonctionne comme une file d’attente. Tant que la première tâche n’est pas finie, la suivante ne démarre pas. Ce schéma paraît logique mais il devient vite un goulet d’étranglement. Dès qu’il faut consulter plusieurs API, analyser différents documents ou lancer plusieurs calculs, le temps s’allonge inutilement. La parallélisation casse ce rythme imposé. Elle consiste à identifier les étapes indépendantes et à les exécuter en même temps, avant de ne regrouper les résultats qu’au moment où c’est vraiment nécessaire.
Ce n’est pas une astuce marginale mais une brique de conception. Dans tout workflow, certaines étapes sont dépendantes, d’autres non. Plus tu es capable de repérer celles qui n’ont pas besoin d’attendre, plus tu accélères ton système. C’est ce qui fait la différence entre un agent lent, qui patine à chaque étape, et un agent qui réagit en temps réel, capable de livrer un résultat complet avant que l’utilisateur n’ait décroché.
Des cas concrets qui parlent
Pour comprendre l’impact de la parallélisation, rien ne vaut des exemples vécus. Imagine un agent chargé de préparer une note d’analyse sur une entreprise. Plutôt que de passer en revue un article de presse, puis d’attendre pour interroger une base financière, puis de scruter les réseaux sociaux, il lance tout en même temps. Les résultats arrivent en parallèle et la synthèse finale se construit sur l’ensemble, sans perte de temps. Tu passes de la recherche fragmentée à une vue d’ensemble livrée en quelques secondes.
Le même principe s’applique à l’analyse de feedback client. Dans un schéma séquentiel, tu dois d’abord traiter la tonalité des avis, puis extraire les mots-clés, puis repérer les urgences, avant de catégoriser. Chaque étape attend la précédente. Avec la parallélisation, toutes ces analyses tournent en même temps et se rejoignent dans un rapport unique. Ce qui prenait des heures devient une opération fluide et quasi instantanée.
Un autre terrain où ça change tout : la planification de voyage. Un agent peut vérifier les vols, chercher les hôtels, lister les événements locaux et proposer des restaurants en parallèle. Résultat : au lieu de quatre temps d’attente cumulés, tu reçois une proposition complète dès que le plus long des appels est terminé. Pour l’utilisateur, la différence est spectaculaire : moins d’attente, plus de valeur perçue.
La création de contenu bénéficie du même effet de levier. Au lieu de générer un objet, puis un corps de texte, puis une image, puis un call-to-action, l’IA peut produire tous ces éléments en parallèle et les assembler à la fin. Tu gagnes en vitesse sans perdre en cohérence. Le même raisonnement vaut pour la validation d’un formulaire : email, téléphone, adresse et filtre de langage peuvent être vérifiés simultanément. La réponse est immédiate, au lieu de ressembler à une série de tests fastidieux.
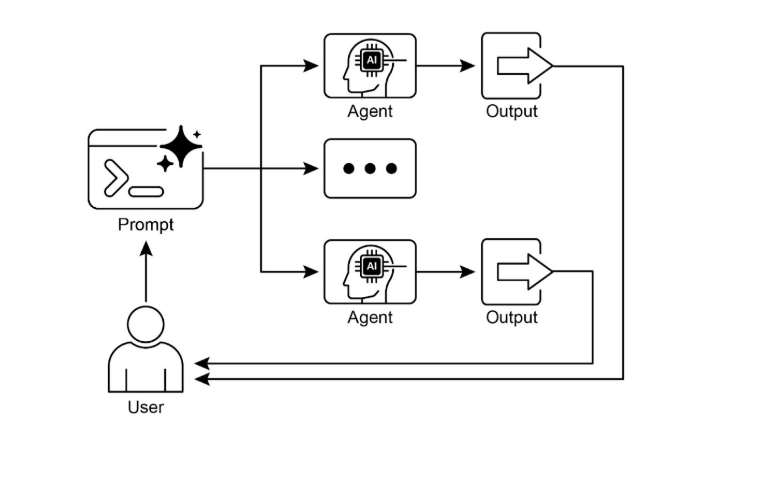
Ces exemples montrent la logique en action : la parallélisation n’est pas une pirouette technique, c’est une façon de rendre un agent réactif, crédible et utile. Elle s’applique partout où plusieurs tâches indépendantes s’accumulent et où le temps de réponse compte autant que la précision.
Bénéfices et limites
Mettre de la parallélisation dans un workflow, c’est offrir une réactivité immédiate. Les utilisateurs ne subissent plus des temps morts interminables : un bot de support répond sans délai, un analyste reçoit une synthèse complète en quelques secondes, un marketeur obtient plusieurs variantes créatives en une seule tentative. Cette vélocité change la perception de l’outil : il ne semble plus mécanique, mais vivant, capable de délivrer une réponse riche avant même que l’attention de l’utilisateur ne se disperse.
Ce gain n’est pas seulement une question de confort, c’est aussi un levier stratégique. Dans un marché où chaque seconde peut compter, réagir plus vite qu’un concurrent équivaut à prendre une longueur d’avance. La parallélisation permet aussi de tirer parti des temps d’attente inévitables liés aux API ou aux bases externes. Au lieu de regarder tourner une roue, l’agent profite de ce temps pour avancer sur d’autres fronts, et tu récupères tous les résultats ensemble.
Il existe toutefois des limites. Certaines étapes dépendent logiquement des précédentes : tu ne peux pas synthétiser un rapport avant d’avoir réuni les données. Orchestrer plusieurs flux simultanés demande aussi plus de soin. Tu dois anticiper les points de convergence, vérifier la cohérence des sorties et t’assurer que rien ne se contredit. Cette complexité supplémentaire alourdit la conception et le débogage, mais elle fait partie du prix à payer pour obtenir un système plus rapide et plus robuste.
La clé, c’est donc de choisir intelligemment. Toutes les tâches n’ont pas besoin d’être parallélisées. Mais dès qu’il y a indépendance entre les étapes, ne pas exploiter cette possibilité revient à brider ton agent. Et dans un environnement où vitesse et pertinence sont synonymes de crédibilité, ce serait dommage de se priver d’un tel avantage.

👉 Si tu veux aller plus loin et apprendre à intégrer concrètement ce principe dans tes propres workflows, abonne-toi à ma newsletter Système Gagnant et retrouve mes vidéos sur YouTube. Chaque semaine, j’y partage des méthodes concrètes pour transformer tes agents IA en systèmes vraiment performants, sans jargon inutile et sans promesses creuses.