
Les RH ne devraient plus lire de CV : automatisez le tri avec cet agent IA n8n (Gmail → Google Drive → OpenAI → Google Sheets)

Scène vue mille fois : 300 CV sur le bureau. On coupe en deux, la moitié direct à la poubelle — “on gagne du temps”.
On peut arrêter la loterie : j'ai conçu cet agent IA qui screene tout, proprement, et garde les meilleurs et te donne un score pout chaque candidature selon la fiche de poste publiée.
La magie du workflow de mon agent IA:
- Extraction automatique des CV depuis les e-mails entrants.
- Comparaison IA de chaque profil contre ta fiche de poste.
- Évaluation profonde sur 8 dimensions (compétences, expérience, séniorité, domaine, réalisations, communication, culture fit, signaux rouges).
- Capture structurée : Date, Lien CV, Prénom, Nom, Email, Forces, Faiblesses, Risk factors, Reward factors, Note globale, Justification détaillée.
- Tout est rangé dans une feuille Google propre pour revue d’équipe.
Impact terrain : ce qui prenait 5+ heures de tri manuel se fait désormais tout seul… et on repère de meilleurs candidats qu’on aurait loupés dans la pile.
À qui ça profite ? Aux équipes qui veulent scaler sans sacrifier la qualité. Que tu embauches sur plusieurs postes ou que tu veuilles dépasser les outils basiques à mots-clés, ce système transforme ton premier tour d’écrémage en avantage stratégique.
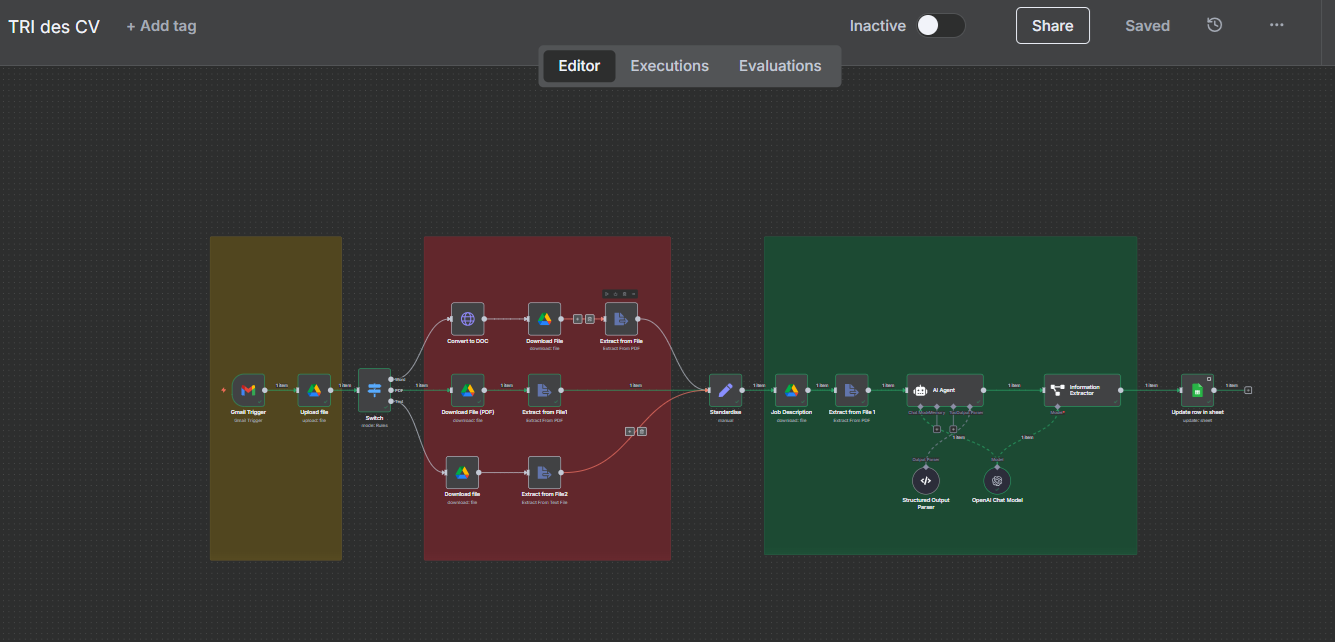
Module 1 : Capture (Gmail Trigger)
Rôle : c’est le filet qui récupère les CV. On écoute la boîte dédiée ou un libellé (ex. candidatures), et on télécharge toutes les pièces jointes.
Astuce : encourage les candidats dans l'appel à candidatures à mettre Prénom Nom — Poste en objet. Tu récupères un nom propre pour le fichier et tu filtres plus finement et
Module 2 : Rangement (Google Drive)
Rôle : un assistant qui met chaque CV au bon endroit, avec un nom propre.
- Dossier dédié :
Resumesdans Drive (garde l’ID sous la main). - Renommage auto :
{{ $json.subject }} Resume→ traçable, partageable. - Bonus : on stocke l’URL Drive pour la feuille Google (revue d’équipe en un clic).
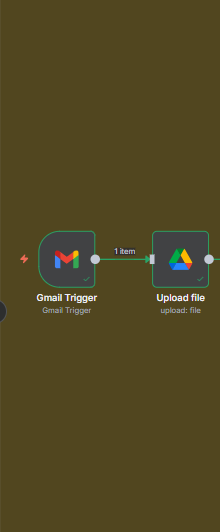
Module 3 : Switch
Rôle : envoyer chaque format sur le bon chemin pour garantir une extraction de texte propre.
- DOCX → branche de conversion (Google Doc → PDF) avant extraction du texte.
- PDF → extraction directe (ajoute un OCR si c’est un scan).
- TXT → lecture directe.
Module 4 : Conversion DOCX → Google Doc → PDF
Pourquoi : extraire du texte propre d’un .docx “exotique” est casse-gueule. La conversion Google → PDF → extraction est plus stable et donc plus fiable pour l’IA.
- Copie & conversion : duplique le fichier DOCX en Google Doc (conversion native).
- Export : télécharge ce Google Doc en PDF.
- Extraction : lis le PDF pour récupérer du
texte brut.
- À surveiller : certains CV DOCX arrivent avec un MIME imprécis. Ajoute un plan B basé sur l’extension (
.docx) si le Switch rate. - OCR si besoin : si le PDF est un scan, intercale un module OCR (Tesseract/Google Vision) avant l’extraction.
- Traçabilité : conserve l’URL Drive du CV converti pour le log final (review d’équipe).
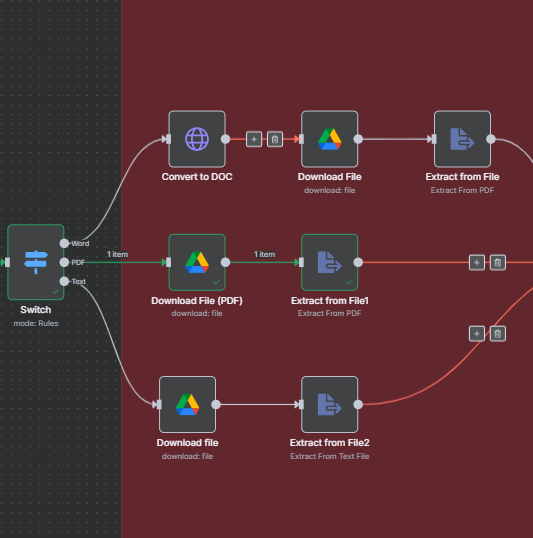
Module 5 : Extraction uniforme (Standardise)
But : tout normaliser dans un seul champ text que l’IA va consommer. On élimine les espaces parasites et on coupe les romans-fleuves.
- Standardisation : place le contenu lu du fichier dans
textet nettoie légèrement (espaces multiples, sauts de ligne). - Contrôle de taille : limite à ~40 000 caractères pour éviter un prompt trop coûteux.
<!-- Exemple de logique (pseudocode) -->
text = (fileText || '').replace(/\s{2,}/g, ' ').trim();
text = text.slice(0, 40000);Pourquoi c’est clé : un champ unique et propre = un agent IA plus précis, moins de bruit.
Module 6 : Référence ( la Fiche de poste JD )
Principe : on ne juge pas un CV tout seul. On le compare strictement à ta JD.
- Téléchargement : récupère le Google Doc de la JD (par son ID).
- Export : convertis-le en PDF puis extraction en texte.
- Préparation : garde ce
textJD à disposition de l’agent IA (contexte).
Format JD recommandé (pour de meilleurs résultats) :
- Mission (1–2 phrases max)
- Must-have (compétences non négociables)
- Nice-to-have (bonus réels, pas cosmétiques)
- Stack/Outils attendus
- Niveau (junior / mid / senior) + portée (scope)
- “No-go” (critères éliminatoires explicites)
Multi-postes : si tu recrutes pour plusieurs rôles, ajoute un Switch en amont pour router vers la bonne JD (par adresse de destination, libellé Gmail, ou mot-clé dans l’objet).
Suite : Module 7 (Évaluation IA + sortie structurée), Module 8 (Contacts), Module 9 (Google Sheets) + test rapide et erreurs fréquentes.
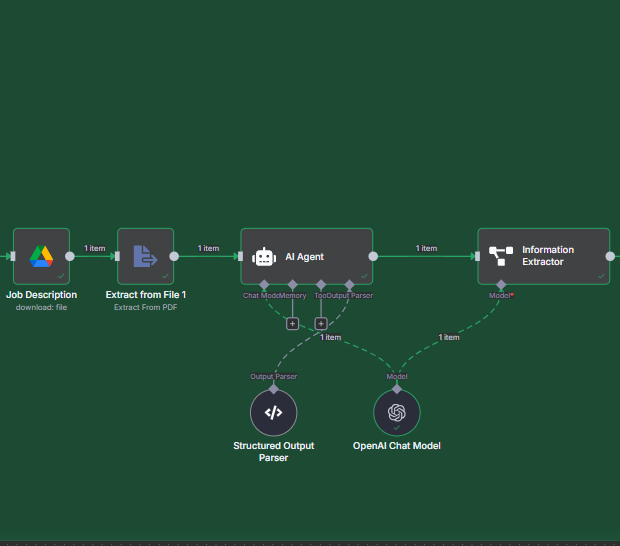
Module 7 : Évaluation IA (Agent + Sortie structurée)
Objectif : obtenir une évaluation utilisable, pas un pavé vague. On force un JSON structuré que Google Sheets peut avaler sans drama.
Modèle : gpt-4.1-mini (rapide, économique, assez “smart” pour ce job).
Contexte fourni à l’IA :
- CV (texte) : issu de l’extraction normalisée du candidat.
- JD (texte) : ta fiche de poste convertie et extraite (Module 6).
Consignes (résumé) : “Tu es un recruteur senior. Compare CV vs JD. Rends une évaluation honnête et concrète. Pas d’invention. Cite le texte quand tu justifies.”
Schéma JSON attendu :
{
"candidate_strengths": [ "..." ],
"candidate_weaknesses": [ "..." ],
"risk_factor": { "score": "Low|Medium|High", "explanation": "..." },
"reward_factor": { "score": "Low|Medium|High", "explanation": "..." },
"overall_fit_rating": 0, // entier 0-10
"justification_for_rating": "..."
}Exemple (tronqué) :
{
"candidate_strengths": ["3 ans en SaaS B2B", "Maîtrise HubSpot"],
"candidate_weaknesses": ["Peu d'ABM", "Pas d'anglais pro"],
"risk_factor": { "score": "Medium", "explanation": "Ramp-up sur ABM" },
"reward_factor": { "score": "High", "explanation": "Excellente exécution outbound" },
"overall_fit_rating": 8,
"justification_for_rating": "Match fort sur must-have; gap sur ABM compensable en 30-45j."
}- Tips de fiabilité : température 0.2–0.4, max tokens raisonnable, et vérifie que l’IA répond bien au schéma (parser structuré côté n8n).
- Anti-hallu : “Ne déduis rien qui n’est pas dans le texte. Si l’info manque, dis-le explicitement.”
Module 8 : Contacts (extraction Prénom / Nom / Email)
Objectif : alimenter ta base de candidats sans copier-coller.
- Source : le texte du CV (ou champs déjà extraits si présents).
- Priorité : d’abord les champs “Email:” / “Contact:”, sinon fallback regex.
Fallback regex (exemple) :
<!-- Email -->
const email = (text.match(/[a-z0-9._%+-]+@[a-z0-9.-]+\.[a-z]{2,}/i) || [])[0] || "";
Astuce : si tes CV proviennent d’un formulaire, récupère le nom propre depuis l’objet de l’e-mail (Prénom Nom — Poste) pour fiabiliser.
Module 9 : Journalisation (Google Sheets)
But : un tableau propre que le manager peut lire en 30s.
Colonnes recommandées :
- Date (ex.
{{ $now.format('dd-MM-yyyy HH:mm') }}) - Resume (URL Drive du fichier)
- First name, Last name, Email
- Strengths, Weaknesses (listes jointes par
"\n") - Risk factor (score + explication)
- Reward factor (score + explication)
- Overall fit (0–10)
- Justification
Lisibilité : mise en forme conditionnelle sur Overall fit (≥8 vert, ≤5 rouge). Fige la ligne d’en-tête.
Test éclair (5 étapes, 10 minutes)
- Envoie un e-mail test avec un CV en pièces jointes (objet
Prénom Nom — Poste). - Vérifie que le fichier est stocké et renommé dans
Drive/Resumes. - Surveille le Switch : bonne branche DOCX/PDF/TXT ?
- Ouvre la sortie de l’Agent IA : JSON conforme au schéma ?
- Contrôle la ligne dans Google Sheets (toutes les colonnes remplies + URL).
KPI à suivre (pour parler “business”)
- Temps moyen de traitement d'une candidature (objectif : -80%).
- Taux d’entretien des candidats notés ≥ 8 (qualité du scoring).
- Taux d’accord recruteur avec l’évaluation IA (calibration continue).
Tu veux la version “clé en main” ?
Je peux t’adapter le screener à tes rôles et à ta culture d’entreprise : Rjoins moi sur instagram @mehdi.ghazzai et sur Youtube Système Gagnant.