95 % des agents IA déçoivent : la compétence simple (et oubliée) qui change tout

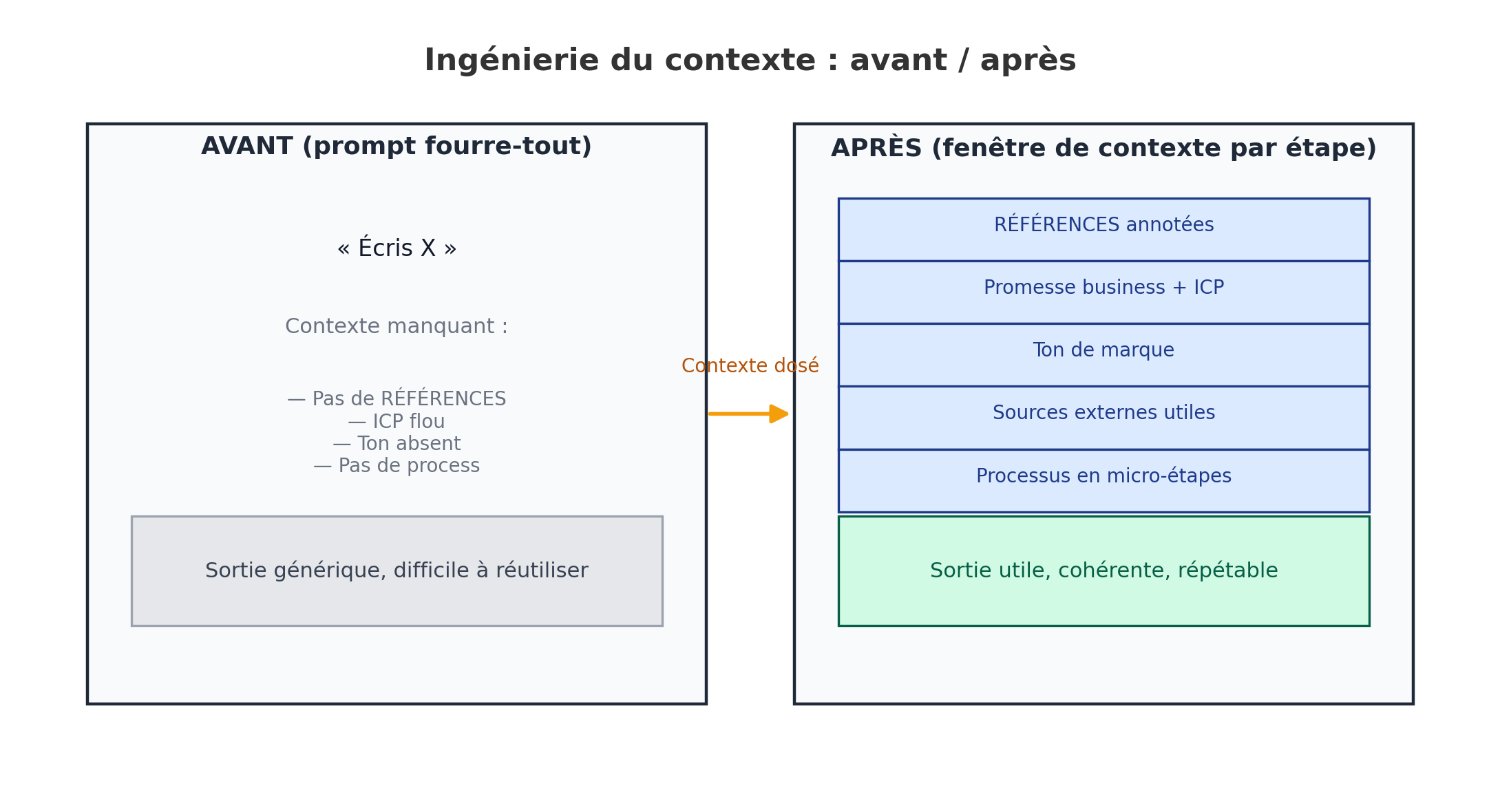
Si tes agents IA crachent des textes génériques, le problème n’est pas « l’IA ». C’est le contexte que tu lui donnes (trop vague, trop tard, mal placé). La bonne nouvelle : corriger ça est simple. Tu vas apprendre à nourrir l’IA étape par étape avec exactement les bonnes infos, ni plus, ni moins, pour obtenir des sorties utiles, cohérentes et répétables.
Ce que tu vas construire
Un agent IA qui suit un petit processus découpé en étapes, avec des variables claires et des points humains là où ça compte.
- Une base Airtable qui contient ton jeu de contexte (promesse, ton, ICP, RÉFÉRENCES), les entrées/sorties de chaque étape et les validations.
- Des instructions d’étape prêtes à l’emploi (un gabarit simple à dupliquer).
- Des tests pour stabiliser la qualité (A/B de prompts, variables, RÉFÉRENCES).
- Une orchestration n8n : 1 workflow = 1 étape, avec pauses pour validation.
Étape 1 : Rassembler 2–3 RÉFÉRENCES (ta boussole de qualité)
Objectif : montrer à l’IA ce que « bon » signifie pour toi. Deux ou trois exemples valent mieux que 20 consignes.
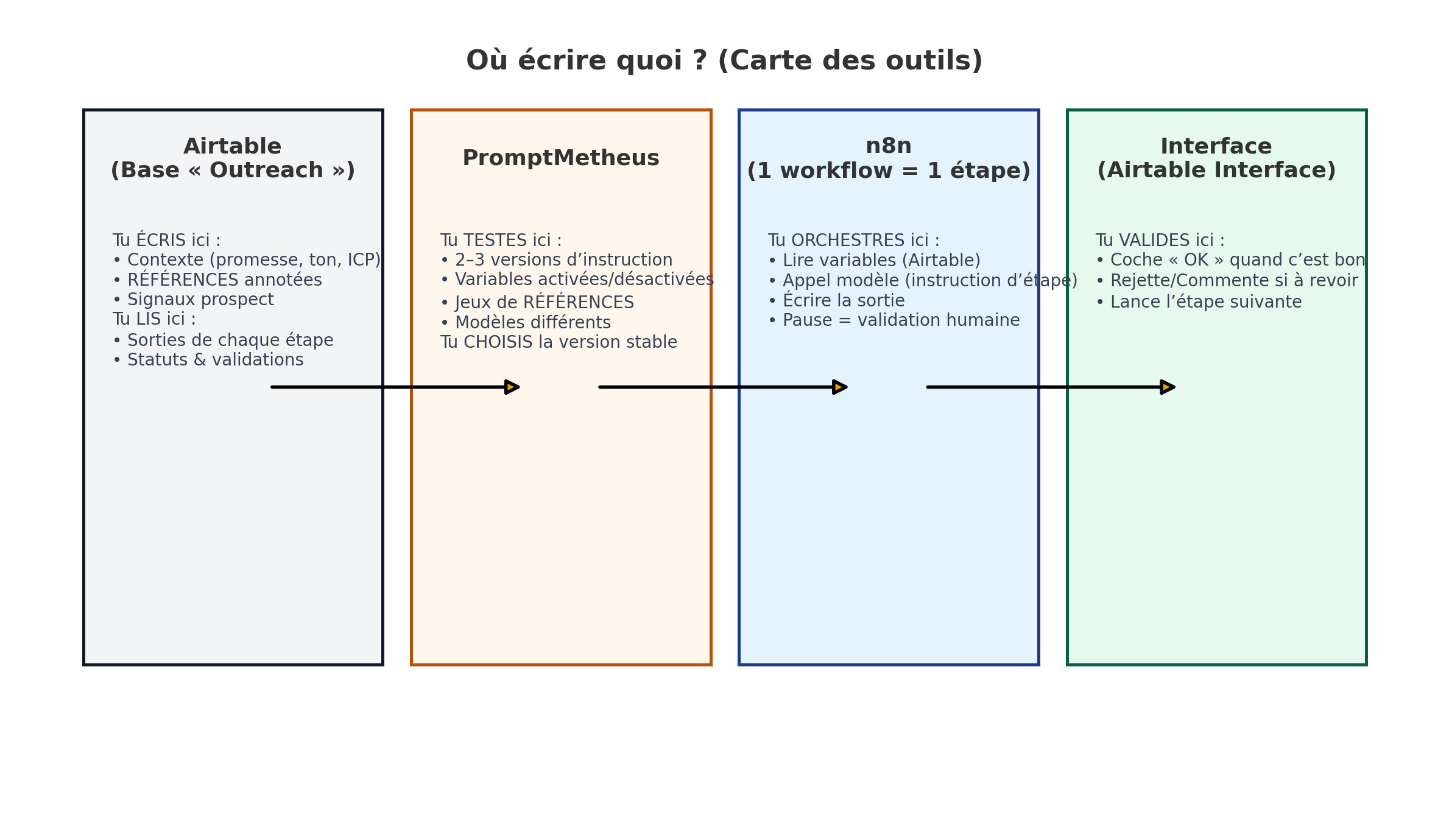
Où écrire : dans Airtable, table Contexte.
promesse(1 phrase) — ex. « Réduire le no-show de 30 % »ton(5 adjectifs) — ex. « direct, concret, sans jargon… »ICP_douleurs(3 puces),ICP_desirs(3 puces),ICP_objections(3 puces)REFERENCE_A,REFERENCE_B(texte + annotation : ce qui est « bon » — structure, ton, CTA)liens_utiles(1–2 max, seulement si nécessaires)
Étape 2 : Diviser le travail en 6 micro-étapes
Un seul prompt « qui fait tout » produit du moyen. Des étapes courtes, avec un objectif simple chacune, produisent du répétable.
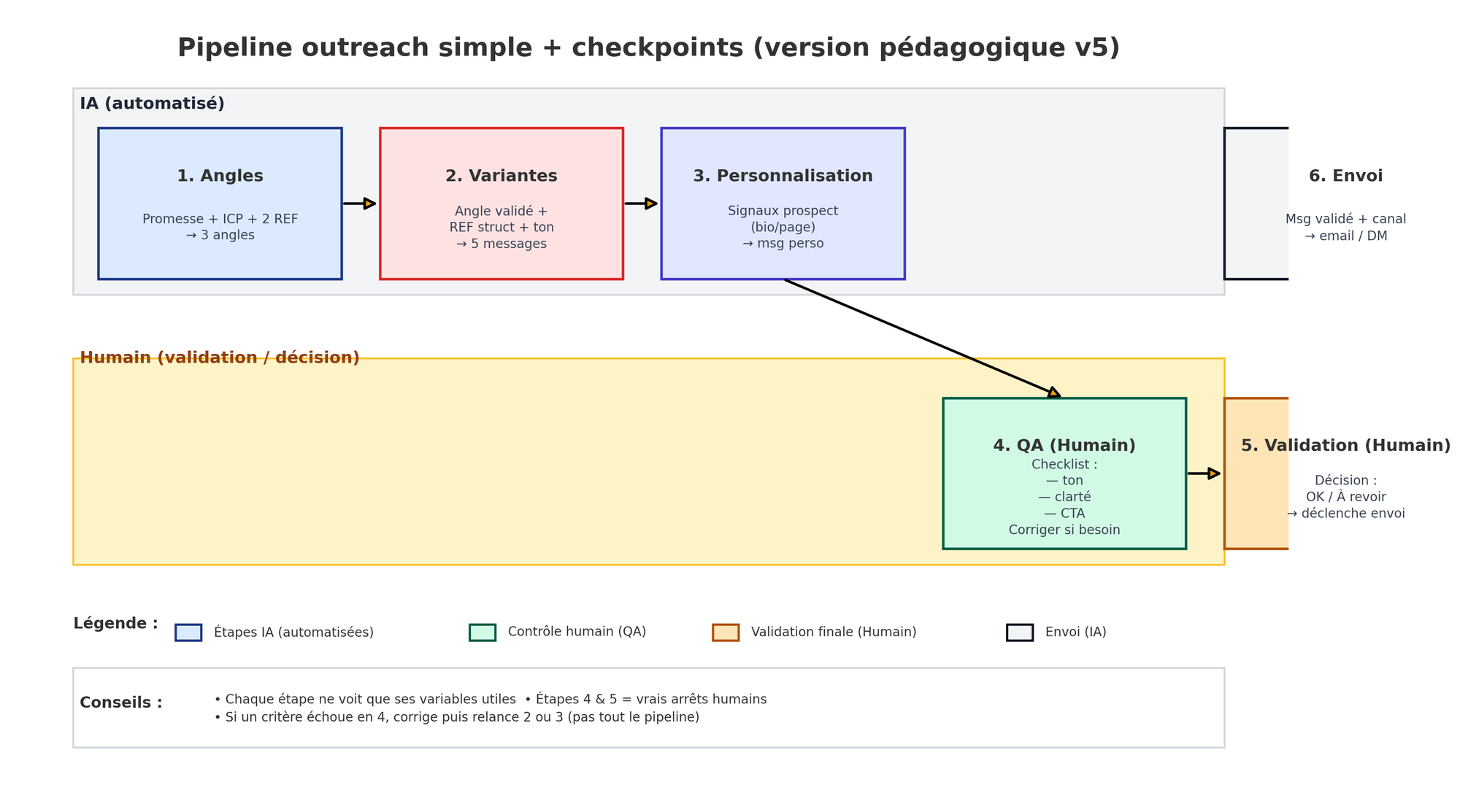
Où écrire : dans Airtable, table Etapes, une ligne par étape avec :
nom(ex. « Angles »)objectif(1 phrase)variables_requises(liste fermée — voir Étape 3)critères_sortie(3 points max)checkpoint_humain(oui/non)
Étape 3 : Préparer le « jeu de contexte »
Tu vas associer les bonnes variables à la bonne étape : et retirer tout le reste.
| Étape | Variables à injecter (Airtable ➜ n8n) | À exclure |
|---|---|---|
| Angles | promesse, ICP_douleurs/ICP_desirs, REFERENCE_A (ton) | Specs techniques |
| Variantes | angle_valide, REFERENCE_A (structure), REFERENCE_B (ton), longueur_max | Historique complet |
| Personnalisation | signaux_prospect (bio/page), bénéfice_clef | Charte éditoriale complète |
| QA | checklist_qualité (ton, clarté, CTA) | Liens non filtrés |
Où écrire : dans Airtable, table Contexte, crée les champs listés ci-dessus. Dans Etapes, référence ces variables dans variables_requises.
Étape 4 : Rédiger l’instruction d’étape (gabarit prêt à copier)
Où écrire : d’abord dans un doc texte (ou directement dans PromptMetheus).
But (1 phrase) : ce que l’étape doit produire.
Variables (liste fermée) : exactement celles de l’étape (voir tableau).
Instruction : « Tu as accès uniquement aux variables listées. Utilise la structure de {REFERENCE_A}, garde le ton {REFERENCE_B}, exprime {promesse} via {ICP_douleurs}/{ICP_desirs}. Écris ≤ {longueur_max}. Interdits : jargon, claims vagues, passif. »
Critères de sortie (3 points) : fidélité au ton RÉFÉRENCE / bénéfice clair / CTA explicite.
Étape 5 : Tester & optimiser (sans te perdre)
Où écrire/faire : dans PromptMetheus (ou à défaut tester « à la main » dans ChatGPT, mais c’est moins rigoureux).
- Crée 3 datasets (3 cas typiques).
- Teste 2–3 versions d’instruction (mêmes variables) ➜ garde la plus stable.
- Active/désactive des variables (ex. sans REFERENCE_A) ➜ mesure l’impact réel.
- Compare 2 jeux de RÉFÉRENCES (A vs B) ➜ garde celui qui guide mieux.
- Si besoin, compare 2 modèles ➜ choisis celui qui tient les critères au meilleur coût.
Stop test : quand l’étape passe tes 3 critères sur les 3 cas, tu verrouilles.
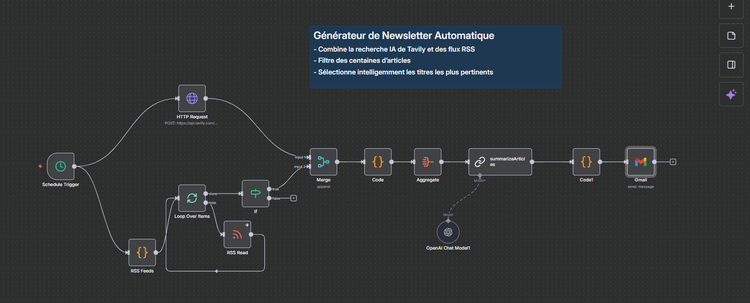
Étape 6 : Orchestration n8n (1 workflow = 1 étape)
Où écrire : dans n8n, crée un workflow par étape :
- Airtable Read → lit les variables depuis la table
Contexte/Prospects. - OpenAI (ou équivalent) → envoie Instruction d’étape + variables.
- Airtable Write → écrit la sortie dans la table
Sorties. - Wait / If → pause jusqu’à ce que l’interface Airtable coche « validé ».
Interface Airtable : affiche la sortie, un bouton « Valider / À revoir » et les commentaires. Tu gardes le contrôle, sans sur-ingénier les cas limites.
Étape 7 : Passer de « service » à « produit »
- Remplace tout contexte en dur par des variables Airtable.
- Garde les workflows séparés par étape (lisibles, testables, maintenables).
- Conserve un journal (versions + notes) pour améliorer tes RÉFÉRENCES et tes instructions.
Récap’ express :
- RÉFÉRENCES (2–3), promesse (1 phrase), ton (5 adjectifs), ICP (3×3), liens utiles (1–2).
- Processus en 6 étapes, variables dosées par étape, checkpoints humains sur QA et Validation.
- Tests AB sur instructions/variables/RÉFÉRENCES/modèles jusqu’à répétabilité.
- Orchestration n8n : 1 workflow = 1 étape, Airtable pour les données + interface.
Tu as maintenant un mode d’emploi clair, des schémas simples, et surtout : où écrire quoi à chaque moment. C’est ça, l’ingénierie du contexte appliquée, et c’est comme ça que tes agents IA cessent d’être génériques.